Skin Irritation/Corrosion Categories by the Globally Harmonized System of Classification and Labeling of Chemicals
Skin Corrosion Category 1 | Skin Irritation Category 2 | Mild Skin Irritation Category 3 | ||
Destruction of dermal tissue: Visible necrosis in at least one of three animals | Reversible adverse effects in dermal tissue | Reversible adverse effects in dermal tissue | ||
Subcategory 1A Exposure: ≤3 minutes Observation: ≤1 hour | Subcategory 1B Exposure: >3 minutes to ≤1 hour Observation: ≤14 days | Subcategory 1C Exposure: >1 to ≤14 hours Observation: ≤14 days | Draize score: ≥2.3 to <4.0 or persistent inflammation until day 14 in at least two of three tested animals | Draize score: ≥1.5 to <2.3 in at least two of three tested animals |
Source: OSHA, A guide to the globally harmonized system of classification and labelling of chemicals (GHS), accessed August 4, 2016, retrieved from https://www.osha.gov/dsg/hazcom/ghsguideoct05.pdf.
Human skin irritation is classically evaluated by visual and palpatory scorings, and more objective measures are obtained, using various methods and bioengineered devices. Attempts to conduct predictive testing for skin irritants should follow a stepwise algorithm and must be directed toward the specific aspect of irritation, which is under consideration. The main predictive methods to evaluate corrosive potency (potential to cause irreversible damage) and irritative potency (potential to cause reversible inflammatory effects) of substances on normal skin are reviewed here, including methods of in vitro testing validated by ECVAM to identify corrosives and differentiate them from noncorrosive substances as well as in vivo methods of corrosion/irritancy evaluation. The test guidelines published by OECD are internationally agreed methods used to identify and characterize hazardous properties of new and existing chemicals. These basic principles can be applied in the assessment of topical toxicity and the relative potency of hazardous chemicals.
Predictive In Vitro Testing
Corrosion Testing
The main principle of corrosion testing is based on the fact that corrosive chemicals damage the SC and barrier function. Three in vitro methods validated by ECVAM are outlined in the following. In addition to Guideline 431 (originally adopted in 2004) (64), two other in vitro test methods for testing of corrosivity have been validated and adopted as OECD Test Guidelines 430 (65) and 435 (66).
The assays that are currently validated for corrosion and irritation testing are listed in Table 23.2, and the methods are outlined in the following (67,68).
• Transcutaneous electrical resistance (TER) test method: TER test method utilizes excised rat skin and identifies corrosive materials by the ability to damage the barrier function, by measuring the reduction in TER.
The test material (150 μL for liquids or sufficient amount of a solid to evenly cover the tested skin and 150 μL of deionized water added on the top) is applied for up to 24 hours to the epidermal surfaces of skin disks (three skin disks are used for each test and control substance) in a two-compartment test system. Skin disks function as the separation between the compartments. Measurements of electrical resistance is the primary end point; a reduction in the TER below a threshold level (5kΩ for rat) indicates corrosivity (69). Detailed guidelines are available at OECD Test Guideline 430: 2013 (65).
• Membrane barrier test method for skin corrosion: Membrane barrier test method for skin corrosion assay utilizes an artificial membrane designed to respond to corrosive substances and may be used to test solids, liquids (with the exception of aqueous materials with a pH between 4.5 and 8.5), and emulsions. The corrosive properties of a material are assessed based on the time required for the tested material to penetrate through this biobarrier (a proteinaceous gel, composed of protein, e.g., keratin, collagen, or mixtures of proteins) and a supporting filter membrane. The system is composed of a synthetic macromolecular biobarrier and a chemical detection system, which can detect a test substance. The tested material (500 μL of a liquid or 500 mg of a finely powdered solid) is evenly applied on the surface of the membrane barrier. Typically, four replicas are produced for each tested substance and its corresponding controls. Controls include a noncorrosive vehicle or solvent used with the test substance; a positive control, typically a chemical with intermediate corrosivity such as sodium hydroxide (GHS Corrosive subcategory 1B) (70); and a negative (noncorrosive) control substance, such as 10% citric acid or 6% propionic acid (66). Corrositex™ is a commercially available membrane barrier test, validated by ECVAM. Detailed guideline is available at OECD Test Guideline 435: 2006 (66).
• Reconstructed human epidermis (RhE) test method: RhE models are three-dimensional (3D) biostructures composed of cultured NHKs, which form a multilayered epidermis including SC. Assessments of skin corrosivity and/or irritancy via RhE models are based on the premise that corrosive substances penetrate through the SC and are toxic to the underlying cells. Corrosive chemicals are identified by their ability to decrease cell viability below defined threshold levels (64). Cell viability is measured by enzymatic conversion of a vital dye into a blue formazan salt that is quantitatively measured after extraction from tissues.
Two or three replicates are used for each test chemical and for the controls in each experiment. Sufficient amount of test chemical should be applied to uniformly cover the epidermis surface; exposure times, incubation temperature, and applied chemical dose vary based on protocol details at OECD Test Guideline 431: 2013 (64). At the end of the exposure period, the test chemical is carefully washed from the epidermis surface with an aqueous buffer of 0.9% NaCl. Then the cell viability in RhE models is measured by the enzymatic conversion of the vital dye MTT [3-(4,5-Dimethylthiazol-2-yl)-2,5-diphenyltetrazolium bromide; Thiazolyl blue] into a blue formazan salt that is quantitatively measured after extraction from tissues. Cell viability values distinguishing corrosives from noncorrosives vary. EpiSkin™, Modified EpiDerm™, and SkinEthic™ test methods allow the subcategorization of corrosive substances into categories 1A, 1B, and 1C, in accordance with the UN GHS (70), but they are unable to distinguish between categories 1B and 1C (due to limited set of known category 1C chemicals) (64).
TABLE 23.2
EURL-ECVAM-Validated In Vitro Test Methods for Skin Irritation/Corrosion Testing
Test Method Name | Corrosion Testing | Irritation Testing |
TER | Distinguish between corrosive and noncorrosive chemicals of different physical forms | N/A |
CORROSITEX™ | Identification of corrosive properties for acids, bases, and their derivative | N/A |
EpiSkin™ | Human skin model | Human skin model |
EpiDerm™ SIT (EPI-200) | Human skin model | Human skin model |
Modified EpiDerm (EPI-200) | Human skin model | Human skin model |
SkinEthic™ (RHE) | Human skin model | Human skin model |
Source: Skin corrosion, accessed August 4, 2016, retrieved from https://eurl-ecvam.jrc.ec.europa.eu/validation-regulatory-acceptance/topical-toxicity/skin-corrosion; Skin irritation, accessed August 4, 2016, retrieved from https://eurl-ecvam.jrc.ec.europa.eu/validation-regulatory-acceptance/topical-toxicityskin-irritation#ecvam-validated-test-methods.
Irritation Testing
• In vitro RhE test method: Assessments of skin irritancy via RhE models are performed using basically the same test methods used to assess corrosivity but with different exposure protocols (64,71). Chemicals that lead to cell viability of ≤50% are considered irritants (for UN GHS Category 2) (72), and those with cell viability >50% are considered nonirritants. Protocol details are available at OECD Test Guideline 439: 2013 (71).
Predictive In Vivo Testing
Acute Dermal Irritation/Corrosion Testing
The assessment of skin corrosivity involving laboratory animals was adopted in 1981 and revised in 1992 and 2002, OECD Test Guideline 404 (73). This method provides information on corrosive potentials of a liquid or solid. Preferred sequential testing strategy is to perform validated in vitro testing prior to this test. New substances are initially evaluated via in vitro testing. In vivo testing is used when data are insufficient on dermal corrosion/irritation potentials of existing substances.
The test is based on the evaluation of skin reactions to a single dose application of a test substance in an experimental animal. The degree of irritation/corrosion is scored at specified intervals for a complete evaluation of the effects. The duration of the study should be sufficient to evaluate the reversibility or irreversibility of the effects.
• Initial test (in vivo dermal irritation/corrosion): In the in vivo dermal irritation/corrosion method, albino rabbit is the preferred animal. The fur of the dorsal area is removed by close clipping 24 hours prior to testing. The test substance is applied in a single dose to a small area of the skin (approximately 6 cm2) of one animal and covered with a gauze patch and a nonirritating tape. The untreated skin areas serve as the control. Substances with a pH of less than 2.0 or more than 11.5 are suspected to be corrosive and should not be tested. The dose applied to the test site is 0.5 mL (liquid) or 0.5 g (solid), and covered with a gauze patch. The first patch is removed after 3 minutes. If no serious skin reaction is observed, a second patch will be placed on a different site for 1 hour. A third patch will be applied for 4 hours if the second patch is tolerated. After the removal of the third patch, the response is evaluated according to the grading in Table 23.3. Initial testing is done using one animal. The animals should be examined for signs of erythema and edema, immediately after patch removal, at 60 minutes and then at 24, 48, and 72 hours.
If a corrosive effect is observed after any of the mentioned sequential exposures, the test is immediately terminated. The animal will be observed for 14 days.
TABLE 23.3
Grading of Dermal Responses (Draize Scale)
Erythema and Eschar Formation | |
No erythema | 0 |
Very slight erythema (barely perceptible) | 1 |
Well-defined erythema | 2 |
Moderate to severe erythema | 3 |
Severe erythema (beef redness) to eschar formation | 4 |
Edema Formation | |
No edema | 0 |
Very slight edema (barely perceptible) | 1 |
Slight edema (edges of area well defined by definite raising) | 2 |
Moderate edema (raised approximately 1 mm) | 3 |
Severe edema (raised more than 1 mm and extending beyond area of exposure) | 4 |
Source: OECD Test No. 404: Acute dermal irritation/corrosion, accessed August 4, 2016, retrieved from http://www.oecd-ilibrary.org/content/book/9789264070622-en; Patil, S. M., Patrick, E., and Maibach, H. I., Animal, human, and in vitro test methods for predicting skin irritation, in Marzulli, F. N., and Maibach, H. I., eds, Dermatotoxicology Methods, CRC Press, Boca Raton, Florida, 89–114, 1998.
Note: The primary irritation index (PII) is calculated by adding up the average of the erythema and edema values. PII < 2: mildly irritating; 2 < PII < 5: moderately irritating; PII > 5: severely irritating (require precautionary labeling).
• Confirmatory test (in vivo dermal irritation): Confirmatory testing will be performed only in substances with no corrosive effect in initial testing. Two additional animals are tested, each with one patch of the test substance for 4 hours. The animals should be examined for signs of erythema and edema at 60 minutes, then at 24, 48, and 72 hours, and for 14 days. The substance is considered an irritant if inflammation persists by the end of this observation period. Additional animals may need to be used to clarify equivocal responses. Protocol details are available at OECD Test Guideline 404: 2002 (73).
The Draize Rabbit Skin Irritancy Test
The Draize rabbit skin, successfully used since the 1940s (74) and established as the basis for the methods mentioned earlier used in Test Guideline 404, involves the application of two semioccluded patches of an undiluted chemical to the shaved back of each animal (typically, three albino rabbits). Each material is tested on two 1 in. square sites on the same animal; one site is intact, and one is abraded in such a way that the SC is opened but no bleeding produced. Each test site is covered with two layers of 1 in. square surgical gauze secured in place with tape. Patches are removed 24 hours after the application, and the test sites are evaluated for erythema and edema using a prescribed scale with the degree of irritation scored for erythema (redness), eschar (scab formation), edema (swelling), and corrosive action at 24, 48, and 72 hours (Table 23.3) (62). Other animal assays assess cumulative irritation caused by some chemicals, which involve both exaggeration and repetition of exposures such as guinea pig immersion test or repeated patch test in a modified rabbit test (75). These tests are not required by regulatory agencies. However, in most instances, these methods have not gained widespread acceptance.
Currently, internationally accepted test methods for skin corrosion and irritation testing include the traditional in vivo animal test (based on Draize rabbit test) as well as in vitro test methods (discussed earlier). Animal testing for cosmetic products has been prohibited in Europe. Testing ban and marketing ban of cosmetic products, which were tested on animals, have been in effect since March 2013 (76).
Human Irritation Testing
Controlled studies with human volunteers have provided meaningful data, and their basic principles are discussed in the following. Predicative irritation assays in humans, using a small area of skin, can be done provided that systematic toxicity (from absorption) is low and informed consent is obtained. Although regulatory agencies do not routinely require testing in humans, human tests are sometimes preferred to animal tests. Test sites generally heal rapidly, within a week or so. More severe reactions should be periodically evaluated over a longer time to ensure resolution and determine inflammatory patterns. Some subjects may develop changes in pigmentation level at the test site following severe responses. Detailed consultation before consenting human subjects are extremely important.
Single-Application Irritation Patch Test
The single-application irritation patch test is used for the assessment of acute irritation potential and involves the application of 0.5 mL (0.5 g for solid test materials) on a 25 mm chamber (0.2 mL and 0.2 g have also been used) (77); solid test materials are moistened to the skin of human volunteers for up to 4 hours. New test materials may be applied for shorter periods (30 minutes to 1 hour), and if tolerated, the exposure time can progressively be increased to 4 hours. When testing new materials, the application of dilutions should be considered (78). Subjects should routinely be instructed to immediately remove patches if unusual discomfort occurs. Tested sites are assessed for the presence of irritation using a grading scale (Table 23.4) at 24, 48, and 72 hours after patch removal (77). Commercial patches, chambers, gauze squares, or cotton bandage material can be used, and patches are applied to either the upper back or the dorsal surface of the upper arm. Patches are secured with surgical tape without wrapping the trunk of the arm. For volatile materials, a relatively nonocclusive tape, such as Micropore® or Scanpore®, should be used (62). This test detects acute skin irritation hazard potential and should be used for hazard classification. It is not intended to predict other types of skin irritant dermatitis, such as cumulative irritant dermatitis (79).
TABLE 23.4
Human Patch Test Grading Scales
Detailed Human Patch Test Grading Scale | |
No apparent cutaneous involvement | 0 |
Faint, barely perceptible erythema or slight dryness (glazed appearance) | ½ |
Faint but definite erythema, no eruptions or broken skin or no erythema but definite dryness; may have epidermal fissuring | 1 |
Well-defined erythema or faint erythema with definite dryness; may have epidural fissuring | 1 ½ |
Moderate erythema, may have a few papules or deep fissures, moderate-to-severe erythema in the cracks | 2 |
Moderate erythema with barely perceptible edema or severe erythema not involving a significant portion of the patch (halo effect around the edges); may have a few papules or moderate to severe erythema | 2 ½ |
Severe erythema (beet red); may have generalized papules or moderate to severe erythema with slight edema (edges well defined by raising) | 3 |
Moderate to severe erythema with moderate edema (confined to patch area) or moderate to severe erythema with isolated eschar formations or vesicles | 3 ½ |
Generalized vesicles or eschar formation or moderate to severe erythema and/or edema extending beyond patch area | 4 |
Simple Patch Test Grading Scale | |
Negative, normal skin | 0 |
Questionable erythema not covering entire area | ± |
Definite erythema | 1 |
Erythema and induration | 2 |
Vesiculation | 3 |
Bullous reaction | 4 |
Source: Hayes, B. B., Patrick, E., and Maibach, H. I., Dermatotoxicology, in Hayes, W., ed., Principles and Methods of Toxicology, fifth edition, CRC Press, Boca Raton, Florida, 1359, 2007; Patil, S. M., Patrick, E., and Maibach, H. I., Animal, human, and in vitro test methods for predicting skin irritation, in Marzulli, F. N., and Maibach, H. I., eds, Dermatotoxicology Methods, CRC Press, Boca Raton, Florida, 89–114, 1998.
Repeat-Application Cumulative Irritation Patch Test
The repeat-application cumulative irritation patch test assesses cumulative irritation. The early work of Marzulli and Maibach (75), Kligman and Wooding (80) and other investigators formed the basis of cumulative irritation assays (78,81). In the original assay, the test material was applied to a 25 mm2 skin of the back via a saturated Webril™ or the skin surface was covered with a viscous material. Patches were removed after 24 hours, sites were evaluated, and a fresh set of patches were reapplied up to 21 days. Basic principles are similar to the single application, and many investigators have developed their version of it. Shorter study times have also been used in the evaluation of surfactants. Many investigators have developed their version (62,80). These methods do not always predict the safety of consumer products, which may be related to intrinsic differences in the reactivity of healthy skin versus damaged or sensitive skin (82).
Exaggerated Exposure Irritation Tests
Irritancy patch testing does not always correlate with the consumers’ experience. Soaps are an example in which patch testing may overpredict the reaction in real life. Immersion testing and antecubital washing test, also known as flex wash, are examples of nonpatch irritancy techniques. Numerous versions of these tests have been used by investigators basically exposing the skin of consented human subjects to different concentrations of detergents for varied amounts of time; the end points are erythema and scaling (78,83,84).
Use of Bioengineering Devices
Multiple commercially available devices are used to measure the biophysical properties of skin. These measures provide objective data to be used in conjunction with the clinical evaluation of inflammatory responses (detailed discussion is in Chapter 1).
• TEWL measurments: TEWL reflects the integrity of the barrier function and can be determined by the use of evaporimeter (85).
• Laser Doppler velocimetry: Laser Doppler velocimetry has been used to quantify the increased blood flow to an inflamed tissue and can be used for the estimation of microcirculation (86).
• Squamometry: Squamometry is a noninvasive, protein-dependent, colorimetric evaluation of the SC and is a sensitive tool in the assessment of nonerythematous irritant dermatitis. An adhesive disk (D-SQUAME) is applied on the skin, and upon removal of the tape, superficial desquamating layer of the SC is harvested. Disks are subsequently stained, and the amount of dye found in the cells are quantified and scaled (87–89).
Phototoxicity
Phototoxicity (photoirritation) refers to tissue inflammation caused by the interaction of certain chemicals with light. Phototoxicity is a nonimmunological, dose-dependent phenomenon that happens when certain chemicals in the skin absorb light and create a pathological irritation. These chemicals may be applied topically or diffused into skin following systemic administration of a drug. The principle of photochemical activation (Grotthuss–Draper Law) states that light must be absorbed by a chromophore for a chemical reaction to happen. Therefore, the first step in the evaluation of the photosafety of a chemical is to have an absorption spectrum conducted. If a substance absorbs light within the range of UV and visible light (290–700 nm), reactive species can be generated, which can harm the tissue. Additional testing is required to assess the photosafety of a product that is intended for topical use or a systemic medication that diffuses to photoexposed skin (90). Validated testing methods for the assessment of phototoxic properties of chemicals are reviewed here.
General Considerations for Photoirritation Testing
Skin is optically heterogeneous, and via reflection, refraction, scattering, and absorption, it can modify the amount of radiation reaching deeper structures (91). These protective properties can be affected by the topical application of different products. Vehicles can decrease the amount of light reflected, scattered, or absorbed (92). They can also affect percutaneous absorption into the skin (92,93). Physical and chemical properties of vehicles can affect absorption, and photoproperties of applied medications, therefore testing of vehicles along with the medications is required by regulating agencies (94).
The approach to the initial evaluation of phototoxicological properties of a substance is summarized in Figure 23.1.
Predictive In Vitro Testing
Screening for UV and Visible Light Absorption
The initial assessment of the photosafety of substances starts by their ability to absorb UV/visible light (wavelengths between 290 and 700 nm). The ability of chemicals to absorb light is an intrinsic property of that specific chemical. To measure how strongly a chemical absorbs light in a given wavelength, molar extinction coefficient (MEC), also called molar absorptivity, is used. MEC is a constant for any given molecule under a specific set of conditions (e.g., solvent, temperature, wavelength) and reflects the efficiency with which a molecule can absorb a photon (typically expressed as liters mol−1 × cm−1) (95).
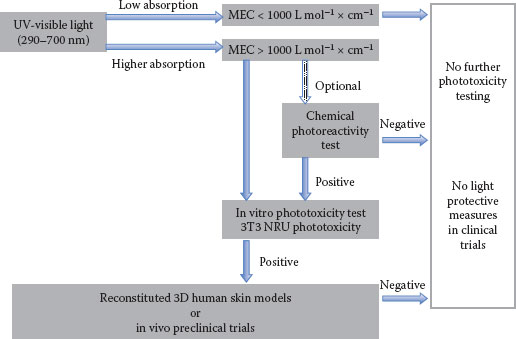
FIGURE 23.1 Outline of phototoxicity assessment strategies.
Photoreactivity Testing Using Chemical Assays
Phototoxicity refers to tissue inflammation caused by the interaction of light and a photoreactive chemical. A photoreactive chemical, at a sufficient tissue concentration, upon exposure to light can generate ROS, singlet oxygen, and/or superoxide. Therefore, ROS generation following visible light or UV exposure can indicate the potential phototoxicity of a chemical.
ROS assay is designed considering the principle mentioned earlier (44,49). This assay has high sensitivity and low specificity, creating many false positives; therefore, a positive result at any concentration would only point out the need for further assessment. On the other hand, the negative result on this assay, provided that the concentration of the test chemical is at least 200 μM, indicates a very low probability of phototoxicity and no further testing is required (94).
Phototoxicity Tests Using In Vitro Assays
1. In vitro 3T3 NRU phototoxicity test (3T3-NRU-PT): In 3T3-NRU-PT, monolayer cell cultures of immortalized mouse fibroblast cell line Balb/c 3T3 are used to assess the cytotoxicity of a chemical in the presence or absence of a noncytotoxic dose of simulated solar light. Cytotoxicity is expressed as a concentration-dependent uptake of neutral red (NR) dye (3-amino-7-dimethylamino-2-methylphenazine hydrochloride) 24 hours after treatment with the test chemical and irradiation (90). NR is a weak cationic dye that penetrates cell membranes by nondiffusion and intracellularly accumulates in the lysosomes. In damaged cells, the alteration of the lysosomal membranes and their fragility by a phototoxic reaction lead to decreased uptake and binding of NR is considered one sequential process. On this bases, viable, damaged, or dead cells can be distinguished. The concentration of test materials resulting in 50% reduction in NR uptake (means that cell viability is reduced by 50%) is called IC50 and is used to evaluate results.
The protocol follows the following steps (full details are available on Test Guideline 432: 2004) (90).
• A permanent mouse fibroblast cell line, Balb/c 3T3, is used.
• To test one chemical, two sets of 96-well plates will be seeded with 1 × 104 cells per well and incubated for 24 hours (37°C; 5% CO2 in air). Both sets will go through the entire test procedure under identical conditions except that one plate is irradiated and one plate is kept in the dark.
•
Related posts:

Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


